 Paper, in PDF format (updated, 328k) |
Slides, in PDF format (400k)
Paper, in PDF format (updated, 328k) |
Slides, in PDF format (400k)
This paper first illustrates the use of mosaic displays and other graphical methods for the analysis of multiway contingency tables. We then introduce several extensions of mosaic displays designed to integrate graphical methods for categorical data with those used for quantitative data.For example, the scatterplot matrix shows all pairwise (marginal) views of a set of variables in a coherent display. One analog for categorical data is a matrix of mosaic displays showing some aspect of the bivariate relation between all pairs of variables. The simplest case shows the marginal relation for each pair of variables. Another case shows the conditional relation between each pair, with all other variables partialled out. For quantitative data this represents (a) a visualization of the conditional independence relations studied by graphical models. and (b) a generalization of partial residual plots.
The conditioning plot, or coplot shows a collection of (conditional) views of several variables, conditioned by the values of one or more other variables. A direct analog of the coplot for categorical data is an array of mosaic plots of the dependence among two or more variables, conditioned (or stratified) by the values of one or more given variables. Each such panel then shows the partial associations among the foreground variables; the collection of such plots show how these associations change as the given variables vary.
Key words: categorical data, conditional independence, coplots, correspondence analysis, graphical models, log-linear models, scatterplot matrix
For some time I have been working on graphical methods for categorical data which aim to be comparable in scope to those available for quantitative data, including exploratory methods, and plots for model-based methods. In this paper I first illustrate the use of mosaic displays and other graphical methods for the analysis of several multiway contingency tables. Second, I introduce several extensions of mosaic displays designed to integrate graphical methods for categorical data with those used for quantitative data.
One essential difference between quantitative data and categorical data lies in the nature of the natural visual representation [ Friendly1995, Friendly1997]. For quantitative, magnitude can be represented by length (in a bar chart) or by position along a scale (dotplots, scatterplots). When the data are categorical, design principles of perception, detection, and comparison [ Friendly1998] suggest that frequencies are most usefully represented as areas.
One final introductory point: the graphics shown here are, of necessity, static graphs, designed to show both the data and some model-based analysis. Their ultimate use will, I believe, be most productive as interactive graphics tightly coupled with the model-building methods themselves. One needs to design good widgets first, however, before learning how to employ them most effectively.
One specialized graphical method using area as the visual mapping of cell frequency is the ``fourfold display'' ( Friendly1994 a, 1994 c; Fienberg1975 ) designed for the display of 2 ×2 (or 2×2 ×k) tables. In this display the frequency nij in each cell of a fourfold table is shown by a quarter circle, whose radius is proportional to �{ nij }, so the area is proportional to the cell count.
For a single 2 ×2 table the fourfold display described here also shows the frequencies by area, but scaled to depict the sample odds ratio, q = (n11 n22 ) /( n12 n21 ). An association between the variables (q � 1) is shown by the tendency of diagonally opposite cells in one direction to differ in size from those in the opposite direction, and the display uses color or shading to show this direction. Confidence rings for the observed q allow a visual test of the hypothesis H0 : q = 1. They have the property that the rings for adjacent quadrants overlap iff the observed counts are consistent with the null hypothesis.
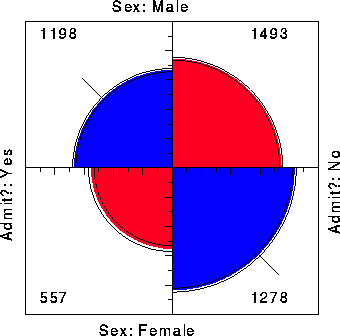
To illustrate, Figure 1 shows aggregate data on applicants to graduate school at Berkeley for the six largest departments in 1973 classified by admission and sex. At issue is whether the data show evidence of sex bias in admission practices [ Bickel et al.1975]. The figure shows the observed cell frequencies numerically in the corners of the display. Thus, there were 2691 male applicants, of whom 1193 (44.4%) were admitted, compared with 1855 female applicants of whom 557 (30.0%) were admitted. Hence the sample odds ratio, Odds (Admit|Male) / (Admit|Female) is 1.84 indicating that males were almost twice as likely to be admitted.
The frequencies displayed graphically by shaded quadrants in Figure 1 are not the raw frequencies. Instead, they have been standardized (by iterative proportional fitting) so that all table margins are equal, while preserving the odds ratio. Each quarter circle is then drawn to have an area proportional to this standardized cell frequency. This makes it easier to see the association between admission and sex without being influenced by the overall admission rate or the differential tendency of males and females to apply. With this standardization the four quadrants will align when the odds ratio is 1, regardless of the marginal frequencies.
The shaded quadrants in Figure 1 do not align and the 99% confidence rings around each quadrant do not overlap, indicating that the odds ratio differs significantly from 1 --- putative evidence of gender bias. The width of the confidence rings gives a visual indication of the precision of the data-if we stopped here, we might feel quite confident of this conclusion.
For example, the admissions data shown in Figure 1 were aggregated over a sample of six departments; Figure 2 displays the data for each department. The departments are labelled so that the overall acceptance rate is highest for Department A and decreases to Department F. Again each panel is standardized to equate the marginals for sex and admission. This standardization also equates for the differential total applicants across departments, facilitating visual comparison.
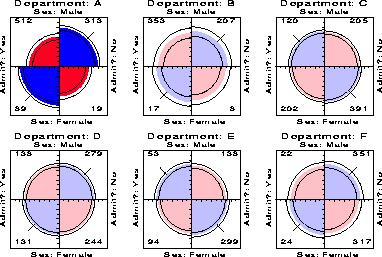
Surprisingly, Figure 2 shows that, for five of the six departments, the odds of admission is essentially identical for men and women applicants. Department A appears to differs from the others, with women approximately 2.86 ( = ( 313/19 ) /(512/89)) times more likely to gain admission. This appearance is confirmed by the confidence rings, which are joint 99% intervals for qc in Figure 2.
This result, which contradicts the display for the aggregate data in Figure 1, is a nice example of Simpson's paradox. The resolution of this contradiction can be found in the large differences in admission rates among departments. Men and women apply to different departments differentially, and in these data women apply in larger numbers to departments that have a low acceptance rate. The aggregate results are misleading because they falsely assume men and women are equally likely to apply in each field.1
Another principle is visual impact-we want the important features of the display to be easily distinguished from the less important [ Tukey1993]. In Figure 2 distinguishes the one department for which the odds ratio differs significantly from 1 by shading intensity, even though the same information can be found by inspection of the confidence rings.
The construction of the mosaic is easily understood as a straightforward application of conditional probabilities. For a two-way table, with cell frequencies nij, and cell probabilities pij = nij / n++, a unit square is first divided into rectangles whose width is proportional to the marginal frequencies ni+, and hence to the marginal probabilities pi = ni+ / n++. Each such rectangle is then subdivided horizontally in proportion to the conditional probabilities of the second variable given the first, pj|i = nij / ni+. Hence the area of each tile is proportional to the observed cell frequency and probability,
| (1) |
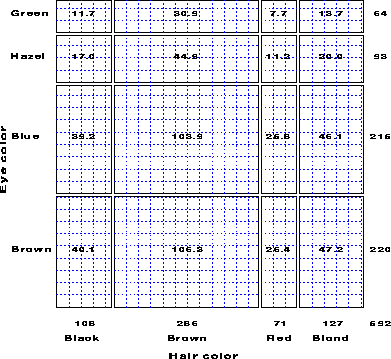
For example, Table 1 shows data on the relation between hair color and eye color among 592 subjects (students in a statistics course) collected by Snee . The Pearson c2 for these data is 138.3 with 9 df, indicating substantial departure from independence.
| Hair Color | |||||
| Eye | |||||
| Color | Black | Brown | Red | Blond | Total |
| Green | 5 | 29 | 14 | 16 | 64 |
| Hazel | 15 | 54 | 14 | 10 | 93 |
| Blue | 20 | 84 | 17 | 94 | 215 |
| Brown | 68 | 119 | 26 | 7 | 220 |
| Total | 108 | 286 | 71 | 127 | 592 |
The basic two-way mosaic for these data, shown in Figure 3, is then similar to a divided bar chart. If hair color and eye color were independent, pij = pi ×pj, and then the tiles in each row would all align. This is shown in Figure 4, which shows a mosaic constructed from the expected frequencies mij = ni+ n+j / n++, under independence.
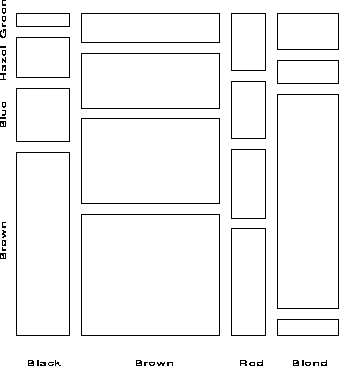
Enhancements to the basic mosaic designed to meet these needs are described below.
Figure 5 gives the extended the mosaic plot, showing the standardized (Pearson) residual from independence, dij = (nij - mij) / �{ mij } by the color and shading of each rectangle: cells with positive residuals are outlined with solid lines and filled with slanted lines; negative residuals are outlined with broken lines and filled with grayscale. The absolute value of the residual is portrayed by shading density: cells with absolute values less than 2 are empty; cells with | dij | � 2 are filled; those with | dij | � 4 are filled with a darker pattern. Under the assumption of independence, these values roughly correspond to two-tailed probabilities p < .05 and p < .0001 that a given value of | dij | exceeds 2 or 4.2
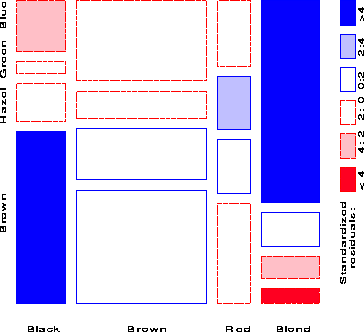
When the row or column variables are unordered, we are also free to rearrange the corresponding categories in the plot to help show the nature of association. For example, in Figure 5, the eye color categories have been permuted so that the residuals from independence have an opposite-corner pattern, with positive values running from bottom-left to top-right corners, negative values along the opposite diagonal. Coupled with size and shading of the tiles, the excess in the black-brown and blond-blue cells, together with the underrepresentation of brown-haired blonds and people with black hair and blue eyes is now quite apparent. Though the table was reordered based on the dij values, both dimensions in Figure 5 are ordered from dark to light, suggesting an explanation for the association. In this example the eye-color categories could be reordered by inspection. A general method [ Friendly1994 b] is to sort the categories by their scores on the largest dimension in a (correspondence analysis) singular value decomposition of residuals.
| (2) |
For example, imagine that each cell of the two-way table for hair and eye color is further classified by one or more additional variables-sex and ethnicity, for example. Then each rectangle can be subdivided horizontally to show the proportion of males and females in that cell, and each of those horizontal portions can be subdivided vertically to show the proportions of people of each ethnicity in the hair-eye-sex group.
Figure 6 shows the mosaic for the three-way table, with hair and eye color groups divided according to the proportions of Males and Females: We see that there is no systematic association between sex and the combinations of hair and eye color-except among blue-eyed blonds, where there are an overabundance of females. (Do they have more fun?)
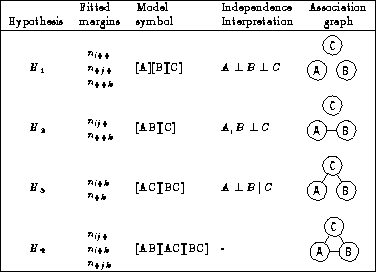
For a three-way table, with variables A, B and C, some of the possible models are described below and summarized in Table 2. I use [ ] notation to list the high-order terms in a hierarchical log-linear model; these correspond to the margins of the table which are fitted exactly. Any other associations present in the data will appear in the pattern of residuals. Here, A ^B is read, ``A is independent of B''. Table 2 also depicts the relations among variables as an association graph, where associated variables are connected by and edge.
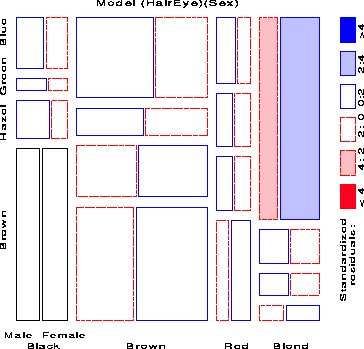
For example, with the data from Table 1 broken down by sex, fitting the joint-independence model [HairEye][Sex] allows us to see the extent to which the joint distribution of hair-color and eye-color is associated with sex. For this model, the likelihood-ratio G2 is 19.86 on 15 df (p = .178), indicating an acceptable overall fit. The three-way mosaic for this model was shown in Figure 6. Any other model fit to this table will have the same tiles in the mosaic since the areas depend on the observed frequencies; the residuals, and hence the shading of the tiles will differ.
The mosaic display is constructed in stages, with the variables listed in a given order. At each stage, the procedure fits a (sub)model to the marginal subtable defined by summing over all variables not yet entered. For example for a three-way table, {ABC}, the marginal subtables {A} and {AB} are calculated in the process of constructing the three-way mosaic. The {A} marginal table can be fit to a model where the categories of variable A are equiprobable (or some other discrete distribution); the independence model can be fit to the {AB} subtable, and so forth. The series of plots can give greater insight into the relationships among all the variables than a single plot alone.
Moreover, the series of mosaic plots fitting submodels of joint independence to the marginal subtables have the special property that they can be viewed as partitioning the hypothesis of mutual independence in the full table [ Friendly1994 b, Goodman1970].
For example, for the hair-eye data, the mosaic displays for the [Hair] [Eye] marginal table (Figure 5) and the [HairEye] [Sex] (Figure 6) table can be viewed as representing the partition
Model df G2 [Hair] [Eye] 9 146.44 [Hair, Eye] [Sex] 15 19.86 ------------------------------------------ [Hair] [Eye] [Sex] 24 155.20
This partitioning scheme for sequential models of joint independence extends directly to higher-way tables. The MOSAICS program [ Friendly1992 b]3 implements a variety of schemes for fitting a sequential series of submodels, including mutual independence, joint independence, conditional independence, partial independence and markov chain models, as shown in Table 3.
| fittype 4 | 3-way | 4-way | 5-way |
| MUTUAL | [A] [B] [C] | [A] [B] [C] [D] | [A] [B] [C] [D] [E] |
| JOINT | [AB] [C] | [ABC] [D] | [ABCE] [E] |
| JOINT1 | [A] [BC] | [A] [BCD] | [A] [BCDE] |
| CONDIT | [AC] [BC] | [AD] [BD] [CD] | [AE] [BE] [CE] [DE] |
| CONDIT1 | [AB] [AC] | [AB] [AC] [AD] | [AB] [AC] [AD] [AE] |
| PARTIAL | [AC] [BC] | [ACD] [BCD] | [ADE] [BDE] [CDE] |
| MARKOV1 | [AB] [BC] | [AB] [BC] [CD] | [AB] [BC] [CD] [DE] |
| MARKOV2 | [A] [B] [C] | [ABC] [BCD] | [ABC] [BCD] [CDE] |
There have been few marine disasters resulting in the staggering loss of life which occurred in the sinking of the Titanic on April 15, 1912 and (perhaps as a result) few that are so widely known by the public. It is surprising, therefore, that neither the exact death toll from this disaster nor the distributions of death among the passengers and crew are universally agreed. Dawson [ Dawson1995 ] presents the cross-classification of 2201 passengers and crew on the Titanic by Age, Gender, Class (1st, 2nd, 3rd, Crew) shown in Table 4 and describes his efforts to reconcile various historical sources. Let us see what we can learn from this data set.
| Class | ||||||
| Survived | Age | Gender | 1st | 2nd | 3rd | Crew |
| No | Adult | Male | 118 | 154 | 387 | 670 |
| Yes | 4 | 13 | 89 | 3 | ||
| No | Child | 0 | 0 | 35 | 0 | |
| Yes | 0 | 0 | 17 | 0 | ||
| No | Adult | Female | 57 | 14 | 75 | 192 |
| Yes | 140 | 80 | 76 | 20 | ||
| No | Child | 5 | 11 | 13 | 0 | |
| Yes | 1 | 13 | 14 | 0 | ||
Examining the series of mosaics for the variables ordered Class, Gender, Age, Survival will show the relationships among the background variables and how these are related to survival. The letters C, G, A, S respectively are used to refer to these variables below.
Figure 7 and Figure 8 show the two-way and three-way plots among the background variables. Figure 7 shows that the proportion of males decreases with increasing economic class, and that the crew was almost entirely male. The three-way plot (Figure 8) shows the distribution of adults and children among the Class-Gender groups. The residuals display the fit of a model in which Age is jointly independent of the the Class-Gender categories. Note that there were no children among the crew, and the overall proportion of children was quite small (about 5 %). Among the passengers, the proportion of children is smallest in first class, largest in third class. The only large positive residuals correspond to a greater number of children among the 3rd class passengers, perhaps representing families travelling or immigrating together.

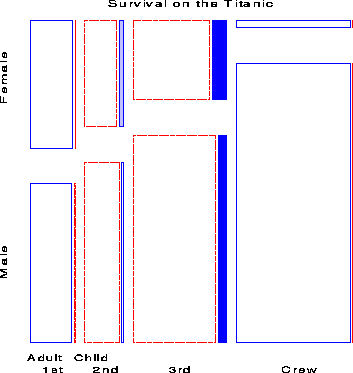
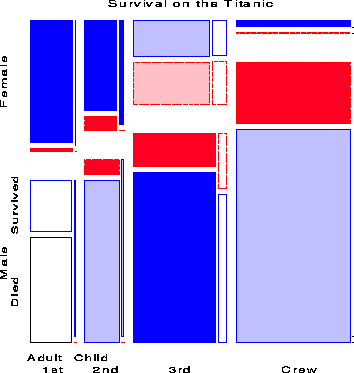
The four-way mosaic, shown in Figure 9, fits the model [CGA][S] which asserts that survival is independent of Class, Gender and Age. This is the minimal null model when the first three variables are explanatory. It is clear that greater proportions of women survived than men in all classes, but with greater proportions of women surviving in the upper two classes. Among males the proportion who survived also increases with economic class. However, this model fits very poorly (G2 (15) = 671.96), and we may try to fit a more adequade model by adding associations between survival and the explanatory variables.
Adding a main effect of each of Class, Gender and Age on Survival amounts to fitting the model [CGA][CS][GS][AS]. That is, each of the three variables is associated with survival, but have independent, additive effects. The mosaic for this model, shown in Figure 10. The fit of this model is much improved (DG2 (5) = 559.4), but still does not represent an adequate fit (G2 (10) = 112.56). There are obviously interactions among Class, Gender and Age on their impact on survival, some of which we have already noted.
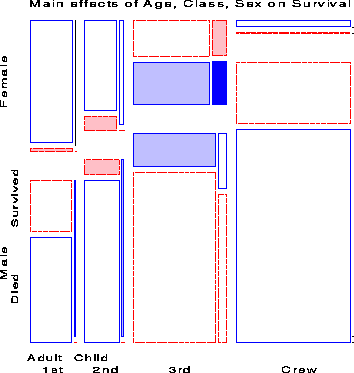
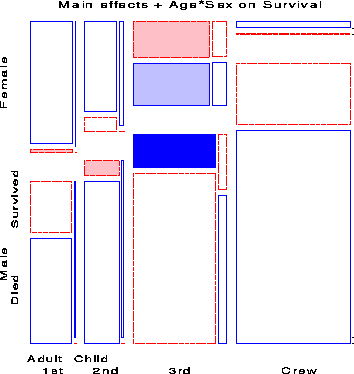
Noting the rubric of ``women and children first'', we next fit the model [CGA][CS][GAS] in which Age and Gender interact in their influence on survival. The mosaic for this model is shown in Figure 11. Adding the association of Age and Gender with survival has improved the model slightly, however the fit is still not good (G2 (9) = 94.54). If we add the interaction of Class and Gender to this (the model [CGA][CGS][GAS]) the The likelihood-ratio chi-square is reduced substantially (G2 (6) = 37.26), but the lack of fit is still significant.
Finally, we try a model in which Class interacts with both Age and Gender to give the model [CGA][CGS][CAS], whose residuals are shown in Figure 12. The likelihood-ratio chi-square is now 1.69 with 4 df, a very good fit, indeed.
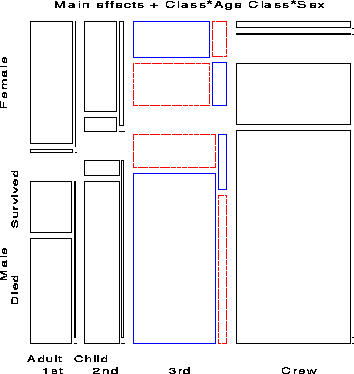
The import of these figures is clear. Regardless of Age and Gender, lower economic status was associated with increased mortality; the differences due to Class were moderated, however, by both Age and Gender. Although women on the Titanic were more likely overall to survive than men, the interaction of Class and Gender shows that women in 3rd class did not have a significant advantage, while men in 1st class did compared to men in other classes. The interaction of Class and Age is explained by the observation that while no children in 1st or 2nd class died, nearly two-thirds in 3rd class died; for adults, mortality increases progressively as economic class declines. Hence, although the phrase ``women and children first'' is melifluous and appeals to our sense of Edwardian chivalry a more adequate description might be ``women and children (according to class), then 1st class men''.
One reason for the wide usefulness of graphs of quantitative data has been the development of effective, general techniques for dealing with high-dimensional datasets. The scatterplot matrix shows all pairwise (marginal) views of a set of variables in a coherent display, whose design goal is to show the interdependence among the collection of variables as a whole, and which allows detection of patterns which could not readily be discerned from a series of separate graphs. In effect, a multivariate data set in p dimensions (variables) is shown as a collection of p (p-1) two-dimensional scatterplots, each of which is the projection of the cloud of points on two of the variable axes. These ideas can be readily extended to categorical data.
A multiway contingency table of p categorical variables, A, B, C,..., also contains the interdependence among the collection of variables as a whole. The saturated log-linear model, [A B C...] fits this interdependence perfectly, but is often too complex to describe or understand. By summing the table over all variables except two, A and B, say, we obtain a two-variable (marginal) table, showing the bivariate relationship between A and B, which is also a projection of the p-variable relation into the space of two (categorical) variables. If we do this for all p (p-1) unordered pairs of categorical variables and display each two-variable table as a mosaic, we have a categorical analog of the scatterplot matrix, called a mosaic matrix. Like the scatterplot matrix, the mosaic matrix can accommodate any number of variables in principle, but in practice is limited by the resolution of our display to three or four variables.
Then the Burt matrix is the symmetric partitioned matrix
| |||||||||||||||||||||||||
Figure 13 shows the mosaic matrix for the bivariate relations in the Titanic data. The bottom row and the rightmost column show the associations between each of the background variables and Survival collapsing over other variables. There are strong associations of all three variables, but particularly for Gender (females more likely to have survived overall) and for Class (``1st'' most likely to have survived overall). Off-diagonal panels show the associations among the classifications of the passengers and crew. The panel in row 3, column 16 is the bivariate relation between Class and Gender, shown earlier in Figure 7. The panels in row 2 show that very few children sailed on the Titanic, and that most were in 3rd class, and female.
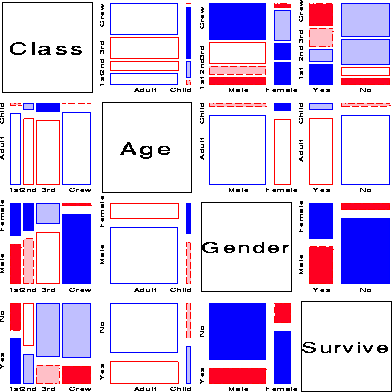
The mosaic matrix in Figure 13 may be compared with the the results of an MCA analysis of the Titanic data. Figure 14 shows the 2-dimensional solution. The positions of the category points for all factors accounts for 50% of the total association (c2 (81) = 15533.4), representing all pairwise interactions among the four factors. The points for each factor have the property that the sum of coordinates on each dimension, weighted inversely by the marginal proportions, equals zero, so that high frequency categories (e.g., Adult) are close to the origin. The first dimension is perfectly aligned with the Gender factor, and also strongly aligned with Survival. The second dimension pertains mainly to Class and Age effects. Considering those points which differ from the origin most similarly (in distance and direction) to the point for Survived, gives the interpretation that survival was associated with being female or upper class or (to a lesser degree) being a child.
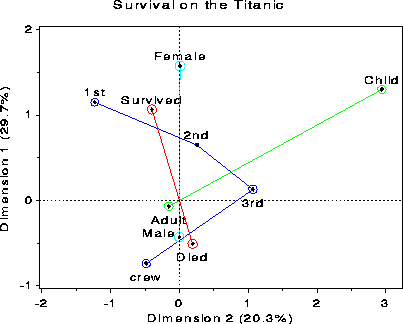
The mosaic matrix, although more complex, captures all of the pairwise associations, while the MCA plot shows only 50% in two dimensions. (A third dimension would account for an additional 17% here.) Most importantly, the pairwise associations are shown explicitly in the mosaic matrix, while they must be inferred from the positions of category points in the MCA plot.
Figure 15 shows the pairwise marginal relations among the variables Admit, Gender and Department in the Berkeley data which were examined earlier in fourfold displays (Figure 1 and Figure 2). The panel in row 2, column 1 shows that Admission and Gender are strongly associated marginally, as we saw in Figure 1, and overall, males are more often admitted. The diagonally-opposite panel (row 1, column 2) shows the same relation, splitting first by gender.7
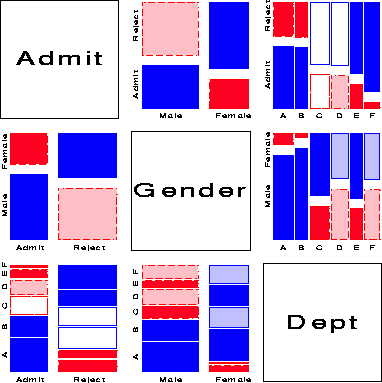
The panels in the third column (and third row) illuminate the explanation for the paradoxical result (see Figure 2) that, within all but department A, the likelihood of admission is equal for men and women, yet, overall, there appears to be a bias in favor of admitting men (see Figure 1) The (1,3) and (3, 1) panels shows the marginal relation between Admission and Department; departments A and B have the greatest overall admission rate, departments E and F the least. The (2, 3) panel shows that men apply in much greater numbers to departments A and B, while women apply in greater numbers to the departments with the lowest overall rate of admission.
Several further extensions are now possible. First, we need not show the marginal relation between each pair of variables in the mosaic matrix. For example, Figure 16 shows the pairwise conditional relations among these variables, in each case fitting a model of conditional independence with the remaining variable controlled. Thus, the (1,2) and (2,1) panels shows the fit of the model [Admit,Dept] [Gender, Dept], which asserts that Admission and Gender are independent, given (controlling for) department. Except for Department A, this model fits quite well, again indicating lack of gender bias.
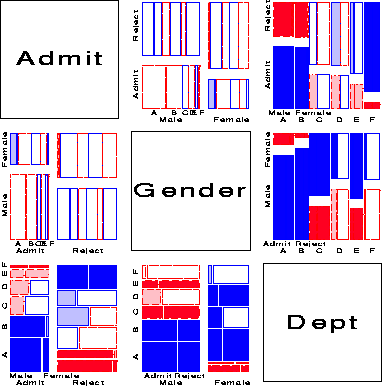
Second, the analogous conditional matrix plot for quantitative variables is of some interest itself. For each pair of variables, Xi, Xj, we plot [(Xi)\tilde] = Xi - [^(Xi)] | others against [(Xj)\tilde] = Xj - [^(Xj)] | others, where ``others'' is the complementary set excluding Xi, Xj. Whittaker shows that Xi, Xj are conditionally independent of the others iff the corresponding element of the inverse covariance matrix S-1 = { sij } is zero,
| |||||||||||||||
Third, the framework of the scatterplot matrix can now be used as a general method for displaying marginal or conditional relations among a mixture of quantitative and categorical variables. For marginal plots, pairs of quantitative variables are shown as a scatterplot, while pairs of categorical variables are shown as a mosaic display. Pairs consisting of one quantitative and one categorical variable can be shown as a set of boxplots for each level of the categorical variable. For conditional plots, we fit a model predicting the row variable from the column variable, partialing out (or conditioning on) all other variables from each.
One analog of the coplot for categorical data is an array of plots of the dependence among two or more variables, stratified by the values of one or more given variables. Each such panel then shows the partial associations among the foreground variables; the collection of such plots show how these change as the given variables vary. Figure 2 is one example of this idea, using the fourfold display to represent the association in 2 ×2 tables.
For categorical data, models of independence fit to the strata separately have the useful property that they decompose a model of conditional independence fit to the whole table. Consider, for example, the model of conditional independence, A^B | C for a three-way table. This model asserts that A and B are independent within each level of C. Denote the hypothesis that A and B are independent at level C(k) by A^B | C(k). Then one can show [ Anderson1991] that
| (4) |
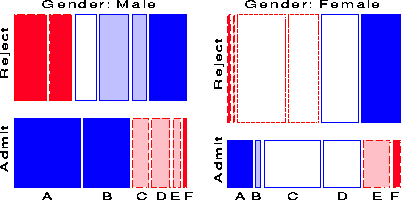
Figure 17 and Figure 18 show two further examples, using the mosaic display to show the partial relations [Admit][Dept] given Gender, and [Admit][Gender] given Dept, respectively. Figure 18 shows the same results displayed in Figure 2: no association between Admission and Gender, except in Dept. A, where females are relatively more likely to gain admission. But one can also see how the proportion admitted decreases regularly from Dept. A to F and how the proportion of females changes across departments. The breakdown of the overall G2 from Eqn. (4) is given in Table 5.
| Dept | df | G2 | p |
| A | 1 | 19.054 | 0.000 |
| B | 1 | 0.259 | 0.611 |
| C | 1 | 0.751 | 0.386 |
| D | 1 | 0.298 | 0.585 |
| E | 1 | 0.990 | 0.320 |
| F | 1 | 0.384 | 0.536 |
| Total | 6 | 21.735 | 0.001 |
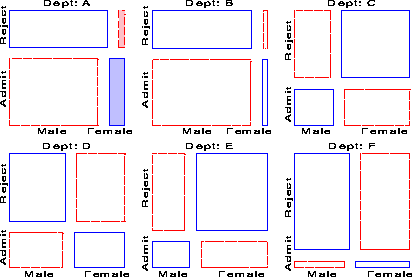
Figure 17 shows that there is a very strong association between Admission and Department-different rates of admission, but also shows two things not seen in other displays: First, the pattern of association is qualitatively similar for both men and women; second the association is quantitatively stronger for men than women-larger differences in admission rates across departments.
drew.tex, processed Jul 17, 1998
1 This explanation ignores the possibility of structural bias against women, e.g., lack of resources allocated to departments that attract women applicants.
2 For exploratory purposes, we do not usually make adjustments (e.g., Bonferroni) for multiple tests because the goal is to display the pattern of residuals in the table as a whole. However, the number and values of these cutoffs can be easily set by the user.
3 http://www.datavis.ca/mosaics/mosaics.html
4 In all cases, the model [A] [B] is fit to a two-way table or marginal table.
5 The representation would be complete if the one-way margins where drawn in the diagonal cells.
6 Rows and columns in the mosaic matrix are identified as in a table or numerical matrix, with row 1, column 1 in the upper left corner.
7 Note that this is different than just the transpose or interchange of horizontal and vertical dimensions as in the scatterplot matrix, because the mosaic display splits the total frequency first by the horizontal variable and then (conditionally) by the vertical variable. The areas of all corresponding tiles are the same in each diagonally opposite pair, however, as are the residuals shown by color and shading.